텐서 플로우(TensorFlow) - 2
1. 형상 조작(Manipulating Shapes)
텐서의 형상을 바꾸는 것은 매우 유용하다.
#1 형상(Shape)은 각 축(차원)의 크기를 표시하는 'TensorShape' 개체를 반환한다.
var_x = tf.Variable(tf.constant([[1], [2], [3]]))
print(var_x.shape)
(3, 1)
#2 Python list로도 변환할 수 있다.
print(var_x.shape.as_list())
[3, 1]
텐서를 새로운 형상으로 바꾸는 것(tf.reshape)은 기본 데이터를 복제할 필요가 없으므로 빠르고 cost가 적다.
#3 텐서를 새로운 shape로 변환
# list를 넘겨 주는 것에 주의
reshaped = tf.reshape(x, [1, 3])
print(x.shape)
print(reshaped.shape)
(3, 1)
(1, 3)
데이터의 레이아웃은 메모리에서 유지되고 요청된 형상이 같은 데이터를 가리키는 새로운 텐서가 작성된다.
TensorFlow는 C-style "행 중심(row-major)" 메모리 순서를 사용한다.
여기서 가장 오른쪽 인덱스를 증가시키는 것이 메모리의 한 단계에 해당한다.
또한, 텐서를 평평하게 하면 어떤 순서로 메모리에 배치되어 있는지 확인할 수 있다.
#4 A `-1` passed in the `shape` argument says "Whatever fits".
print(tf.reshape(rank_3_tensor, [-1]))
tf.Tensor(
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29], shape=(30,), dtype=int32)
보통, tf.reshape의 대부분의 용도는 인접 축을 결합/분할하는 것이다.(또는 1을 추가/제거).
2. DTypes에 대한 추가 정보
tf.Tensor의 데이터 유형을 검사하려면, Tensor.dtype속성을 사용한다.
Python 객체에서 tf.Tensor를 만들 때 선택적으로 데이터 유형을 지정할 수 있다.
아니면, TensorFlow는 데이터를 나타낼 수 있는 데이터 유형을 선택한다.
TensorFlow는 Python 정수를 tf.int32로, Python 부동 소수점 숫자를 tf.float32로 변환한다.
다른 방법으로는 TensorFlow는 NumPy가 배열로 변환할 때 사용하는 것과 같은 규칙을 사용한다.
또한, 유형 별로 캐스팅할 수 있다.
#5 Dtype Code
the_f64_tensor = tf.constant([2.2, 3.3, 4.4], dtype=tf.float64)
the_f16_tensor = tf.cast(the_f64_tensor, dtype=tf.float16)
# uint8로 캐스트하고 정확한 소수점을 잃음.
the_u8_tensor = tf.cast(the_f16_tensor, dtype=tf.uint8)
print(the_u8_tensor)
tf.Tensor([2 3 4], shape=(3,), dtype=uint8)
3. 브로드캐스팅(Broadcasting)
브로드캐스팅은 NumPy의 해당 특성에서 빌린 개념이다.
요약하자면, 특정 조건에서 작은 텐서는 결합된 연산을 실행할 때 더 큰 텐서에 맞게 자동으로 “확장(streched)”된다는 것이다.
가장 일반적인 예는 스칼라에 텐서를 곱하거나 추가하려고 할 때다.
이 경우, 스칼라는 다른 인수와 같은 형상으로 브로드캐스트(Broadcast)된다.
#6 브로드캐스팅(Broadcasting)
x = tf.constant([1, 2, 3])
y = tf.constant(2)
z = tf.constant([2, 2, 2])
# 모두 동일한 계산
print(tf.multiply(x, 2))
print(x * y)
print(x * z)
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
tf.Tensor([2 4 6], shape=(3,), dtype=int32)
마찬가지로, 크기가 1인 축은 다른 인수와 일치하도록 확장할 수 있다.
대부분 브로드캐스팅은 브로드캐스트 연산으로 메모리에서 확장된 텐서를 구체화하지 않으므로 시/공간적인 면에서 효율적이다.
tf.broadcast_to를 사용하여 브로드캐스팅이 어떤 모습인지 알 수 있다.
#7 tf.broadcast_to
print(tf.broadcast_to(tf.constant([1, 2, 3]), [3, 3]))
tf.Tensor(
[[1 2 3]
[1 2 3]
[1 2 3]], shape=(3, 3), dtype=int32)
tf.convert_to_tensor
tf.matmul 및 tf.reshape와 같은 대부분의 ops는 클래스 tf.Tensor의 인수를 사용한다.
그러나 위의 경우, 텐서 형상의 Python 객체가 수용됨을 알 수 있다.
전부는 아니지만 대부분의 ops는 텐서가 아닌 인수에 대해 convert_to_tensor를 호출한다.
변환 레지스트리가 있어 NumPy의 ndarray, TensorShape, Python 목록 및 tf.Variable과 같은 대부분의 객체 클래스는 모두 자동으로 변환된다.
자세한 내용은 tf.register_tensor_conversion_function을 참조
4. 비정형 텐서(Ragged Tensors)
어떤 축을 따라 다양한 수의 요소를 가진 텐서를 “비정형(ragged)”이라고 한다.
비정형 데이터에는 tf.ragged.RaggedTensor를 사용한다.
비정형 텐서는 정규 텐서로 표현할 수 없다.
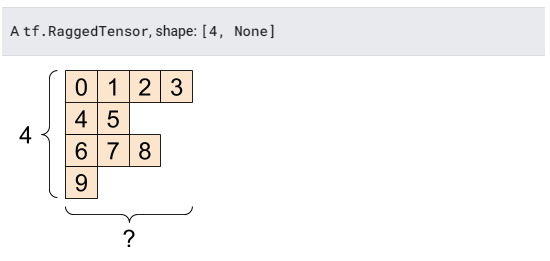
#8 비정형 텐서(Ragged Tensors)
ragged_tensor = tf.ragged.constant(ragged_list)
print(ragged_tensor)
<tf.RaggedTensor [[0, 1, 2, 3], [4, 5], [6, 7, 8], [9]]>
5. 문자열 텐서(String tensors)
tf.string은 dtype이며, 텐서에서 문자열(가변 길이의 바이트 배열)과 같은 데이터를 나타낼 수 있다.
문자열은 원자성이므로 Python 문자열과 같은 방식으로 인덱싱할 수 없다.
문자열의 길이는 텐서의 축 중의 하나가 아니다.
문자열을 조작하는 함수에 대해서는 tf.strings를 참조.
다음은 스칼라 문자열 텐서입니다.
#9 스칼라 문자열 텐서(Scalar String Tensors)
scalar_string_tensor = tf.constant("Gray wolf")
print(scalar_string_tensor)
tf.Tensor(b'Gray wolf', shape=(), dtype=string)
문자열의 벡터는 다음과 같다.
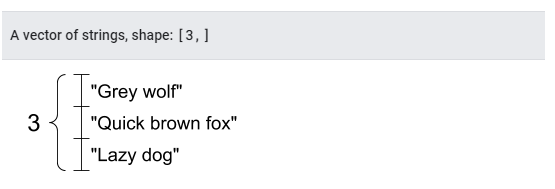
#10 문자열 텐서
# 다른 길이 문자열 텐서 3개여도 괜찮다.
tensor_of_strings = tf.constant(["Gray wolf",
"Quick brown fox",
"Lazy dog"])
# 모양은 (3,)이다.
# 문자열 길이는 포함되지 않는다.
print(tensor_of_strings)
tf.Tensor([b'Gray wolf' b'Quick brown fox' b'Lazy dog'], shape=(3,), dtype=string)
위의 출력에서 b 접두사는 tf.string dtype이 유니코드 문자열이 아니라 바이트 문자열임을 나타낸다.
문자열이 있는 일부 기본 함수는 tf.strings을 포함하여 tf.strings.split, tf.string.to_number 등에서 찾을 수 있다.
tf.cast를 사용하여 문자열 텐서를 숫자로 변환할 수는 없지만, 바이트로 변환한 다음 숫자로 변환할 수는 있다.
tf.string dtype은 TensorFlow의 모든 원시 바이트 데이터에 사용된다.
tf.io 모듈에는 이미지 디코딩 및 csv 구문 분석을 포함하여 데이터를 바이트로 변환하거나 바이트에서 변환하는 함수가 포함되어 있다.
6. 희소 텐서(Sparse tensors)
가지고 있는 데이터가 넓은 임베드 공간(wide embedding space)과 같이 데이터가 희소할 수 있다.
TensorFlow는 tf.sparse.SparseTensor 및 관련 연산을 지원하여 희소 데이터를 효율적으로 저장한다.
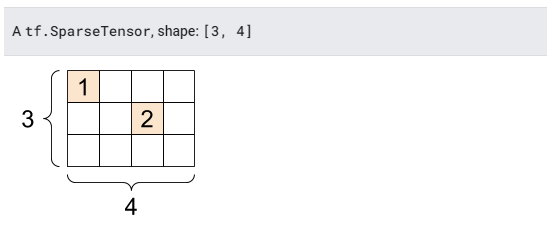
#11 희소텐서
# 메모리 효율적인 방식으로 인덱스 별로 값을 저장한다.
sparse_tensor = tf.sparse.SparseTensor(indices=[[0, 0], [1, 2]],
values=[1, 2],
dense_shape=[3, 4])
print(sparse_tensor, "\n")
# 우리는 희소 텐서를 밀집(dense)하게 변환할 수 있다.
print(tf.sparse.to_dense(sparse_tensor))
SparseTensor(indices=tf.Tensor(
[[0 0]
[1 2]], shape=(2, 2), dtype=int64), values=tf.Tensor([1 2], shape=(2,), dtype=int32), dense_shape=tf.Tensor([3 4], shape=(2,), dtype=int64))
tf.Tensor(
[[1 0 0 0]
[0 0 2 0]
[0 0 0 0]], shape=(3, 4), dtype=int32)
이것을 마지막으로 텐서플로우(TensorFlow)의 공식 홈페이지 텐서(tensor)에 대한 가이드 내용이다.
더욱 자세하고 다양한 텐서에 관한 내용을 보려면 밑의 URL을 통해 살펴보는 것을 추천한다.
https://www.tensorflow.org/guide/
또한, 참고하자면 한국어로 읽는 것보다 영어 원문으로 읽는 것이 확실히 정확하고 자세한 내용을 알 수 있다.
이미지 출처: (https://www.tensorflow.org/guide/tensor/)